网络参数 RSS、RPS、RFS、aRFS 学习总结
 次阅读
次阅读 最近学习,发现网络参数(包括内核参数、网卡参数)非常多,搞得人云里雾里,非常头大。因此打算在这里对学习到的东西做个总结,方便知识的梳理和以后的复习。
Receive Side Scaling (RSS)
RSS 是一个 Linux 网络协议栈中的调度机制。它的主要作用是将数据包路由到不同的接收队列,进而由该队列所对应的 CPU 进行处理,从而实现对数据包处理的负载均衡。
在硬件上,通常使用 hash 函数(一般是 Toeplitz hash)和长度为 128 (2^7) 的置换表来实现。具体做法是,首先将网络和传输层头部的一些信息(如地址端口四元组)通过 hash 函数计算出一个 hash 值,然后取该 hash 值的后 7 位。将这 7 位数作为索引,在置换表中寻找相应的值,该值即为相应的队列。
|
|
网卡的置换表可以通过命令 ethtool --show-rxfh-indir <eth0> 来获取,例子如下:
|
|
可见一共有 128 条表项,完全均匀分配给了队列 rx-0 → rx-3。该表可通过命令 ethtool —set-rxfh-indir 进行配置。
上述机制实现了从数据包到队列的对应,为了真正实现负载均衡,我们还需要协调好从队列到 CPU 的对应关系。又因为每个队列对应一个中断(参考上一篇),所以我们可以通过中断号绑定的方式来实现队列和 CPU 的对应。关于此,请参考关于此,请参考 理解 CPU、中断、队列、进程的绑定关系 - 麋鹿博客 (Elk blog) | 一个分享知识和乐趣的地方 。
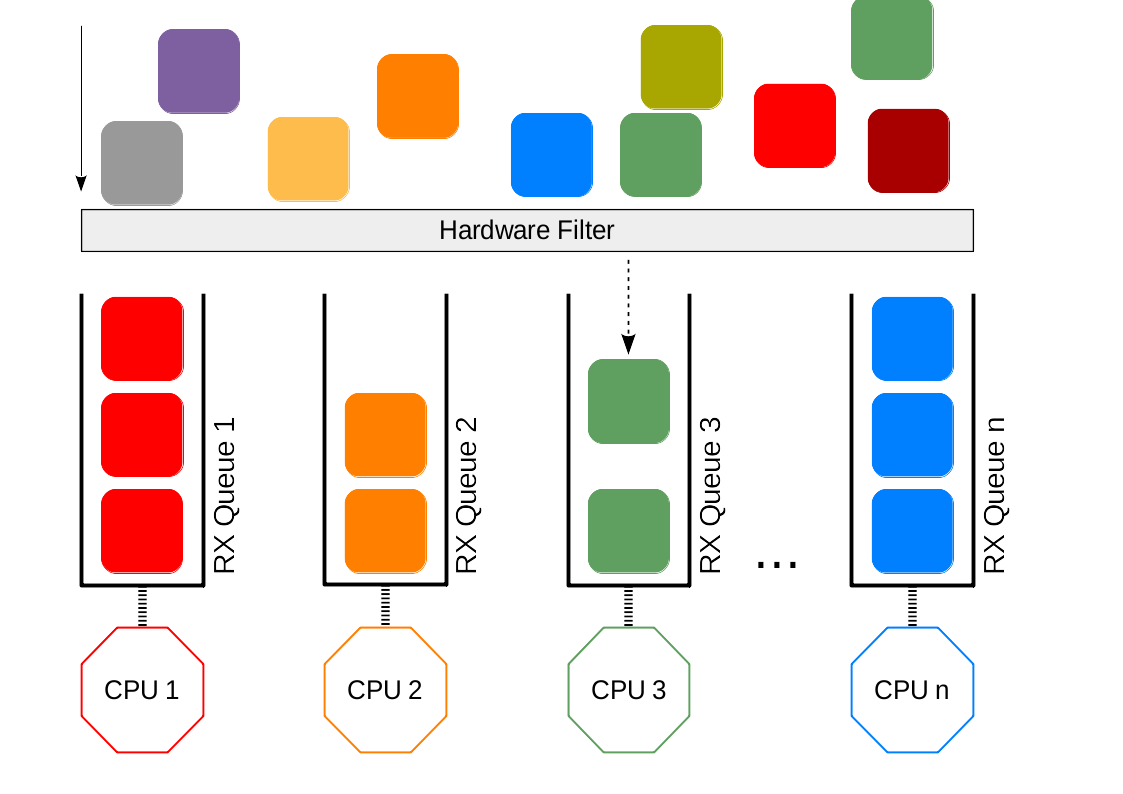
本文RSS、RPS、RFS、aRFS图片来源:Linux Network Scaling: Receiving Packets (garycplin.blogspot.com)
该文档 给出建议,想要实现低延时,应该配置 CPU 数量的队列(即每个 CPU 一个)。对此,笔者的理解是,如果队列数量少了,则可能会有 CPU 闲着,处理不够及时。队列数量多了也没用,因为 CPU 就那么多。
针对以高速率为目的的网络,文档建议使用尽可能少的队列,在这种配置下,不会出现接收队列因为一个 CPU 饱和而溢出的情况。因为在启用中断合并(如 NAPI)的情况下,队列越多,中断数越多。
Receive Packet Steering (RPS)
RPS 逻辑上是 RSS 的软件实现,但又不完全一样。RSS 可以为每个数据包选择接收队列,因此也就选择了相对应的执行中断处理的 CPU;而在 RPS 中,中断由默认队列触发,中断处理函数结束之后,选择进行后续协议处理的 CPU。
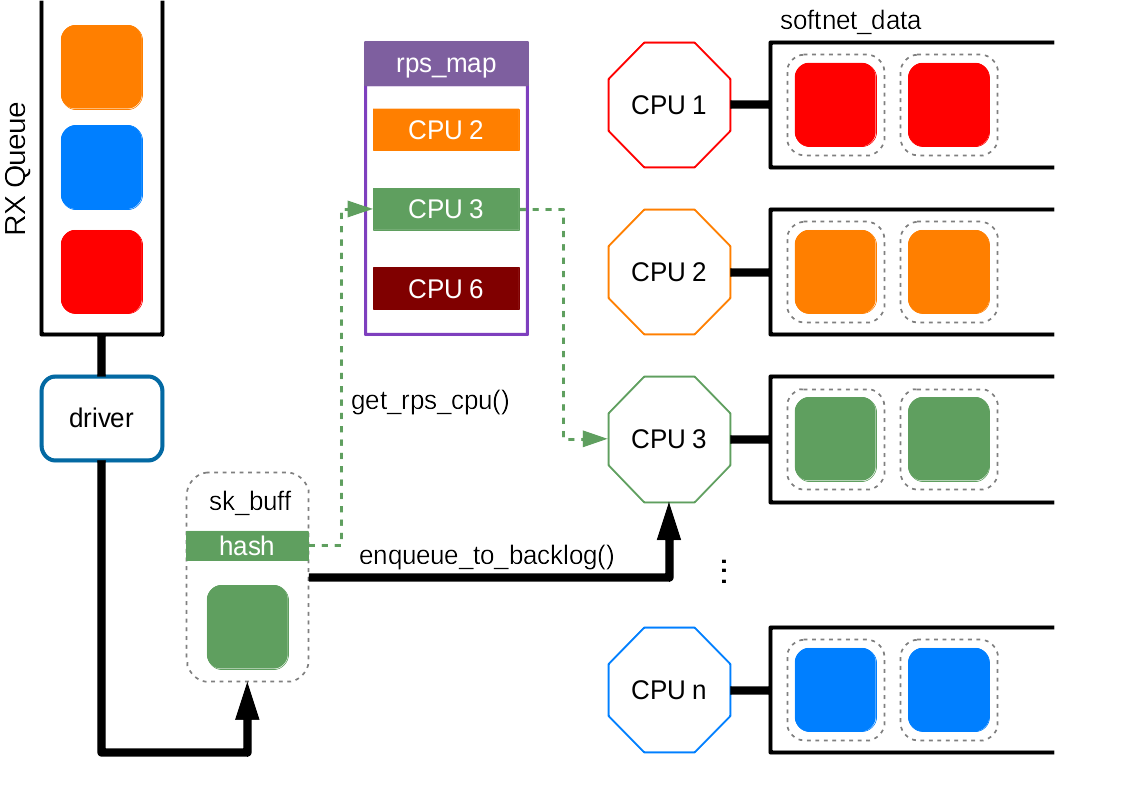
RPS 不会增加额外的硬件设备中断,但是引入了处理器间中断(IPI)。
— Scaling in the Linux Networking Stack — The Linux Kernel documentation
RPS 使用和 RSS 相同的 hash 计算方式,并且每个队列对应一个 CPU 列表。使用计算得到的 hash 值模上 CPU 列表的长度就得到了 CPU 号。当确定了新的 CPU 之后,数据包会被放置到相应 CPU 的 backlog 队列中。随后在新的 CPU 上触发一个 IPI 中断,告诉该 CPU 有 RPS 过来的新包需要其处理。
|
|
在编译内核时通过设置 CONFIG_RPS 参数来设置是否支持 RPS 功能,系统默认为开。但是需要为想要使用 RPS 功能的队列配置上面提到的 CPU 列表。
RPS 配置文件为 /sys/class/net/<device>/queue/<rx-queue>/rps_cpus ,其中 <device> 表示网络设备,如 eth0 ,<rx-queue> 表示接收队列,如 rx-0。
该文件中存储的是一个十六进制的 bitmap。每一个二进制比特代表一个 CPU,最右边对应序号最小的 CPU(即 CPU0),最左边代表最大的。(参考上一篇)
每个队列的配置默认为 0,即关闭 RPS 功能。如果要打开,用户可以根据规则自行设置。
如果网卡只支持单个队列,并且有多个 CPU 的的话,在 NUMA 系统中,一般将 RPS CPU 设置为在相同 domain 的 CPU,非 NUMA 系统就无所谓了,因为设置为每一个 CPU 的性能都是一样的。
对于多队列网卡,一般系统不会同时启用 RSS 和 RPS,因为这没什么好处。但也有例外,比如网卡所支持的队列数目少于 CPU 数,也就是每个 CPU 还分不到一个接收队列,那么使用 RPS 可能会使得 CPU 的任务分布更高效。
Receive Flow Steering (RFS)
以上机制很好地保证了数据包处理的负载均衡,可以将处理任务合理的分配到所有的 CPU 上。
但是,有时候我们还需要考虑其他的因素。比如,网卡收到了属于一个运行在 CPU0 上的进程的数据包,那么这些数据包被 CPU0 处理会比其他 CPU 处理更高效。
原因很简单直观,数据在 CPU 内传递比跨 CPU 传递要更节省时间。因此,我们希望数据包尽量能够被其所属的进程所在的 CPU 处理,至少能够被同属一个 NUMA 域的 CPU 处理。
RFS 机制就是为了实现这一点。该机制利用了与 RSS/RPS 类似的 hash 和查找策略,即使用 hash 函数根据包头信息计算得到一个 hash 值,然后作为索引查表。但与之不同的是,RFS 所查找的匹配表(rps_sock_flow_table)中存储的是数据包所属进程所在的 CPU。
|
|
回顾一下,RPS/RSS 中存储的是预先配置好的 CPU 列表。
如果能查找到有效的 CPU,就按照与 RPS 相同的机制,将数据包入队到 CPU 对应的 backlog 队列中;如果查找不到,那么就直接按照 RPS 机制转发。
与 RPS 预先配置好的 CPU 列表不同,rps_sock_flow 表是动态更新的。如果有数据包的收发操作,如 inet_recvmsg(), inet_sendmsg(), inet_sendpage(), tcp_splice_read() 等操作,则会插入新的值。类似的情况还发生在进程被调度到新的 CPU 的时候。这时候就需要更新匹配表中的值。如果原来的 CPU 队列上还有未处理完的数据包,那么就会发生乱序。
为了避免乱序,RFS 使用了另一个表 —— rps_dev_flow 表,每个网卡队列对应一个该表。该表的索引依旧是包头的 hash 值,每个索引对应两个字段:1) 现在的 CPU(也就是该数据包所属流已经把数据包放在其队列上等待其内核处理的 CPU)号。2) 当该流最后一个数据包到达后,该 CPU 的 backlog 队列的尾计数器值。
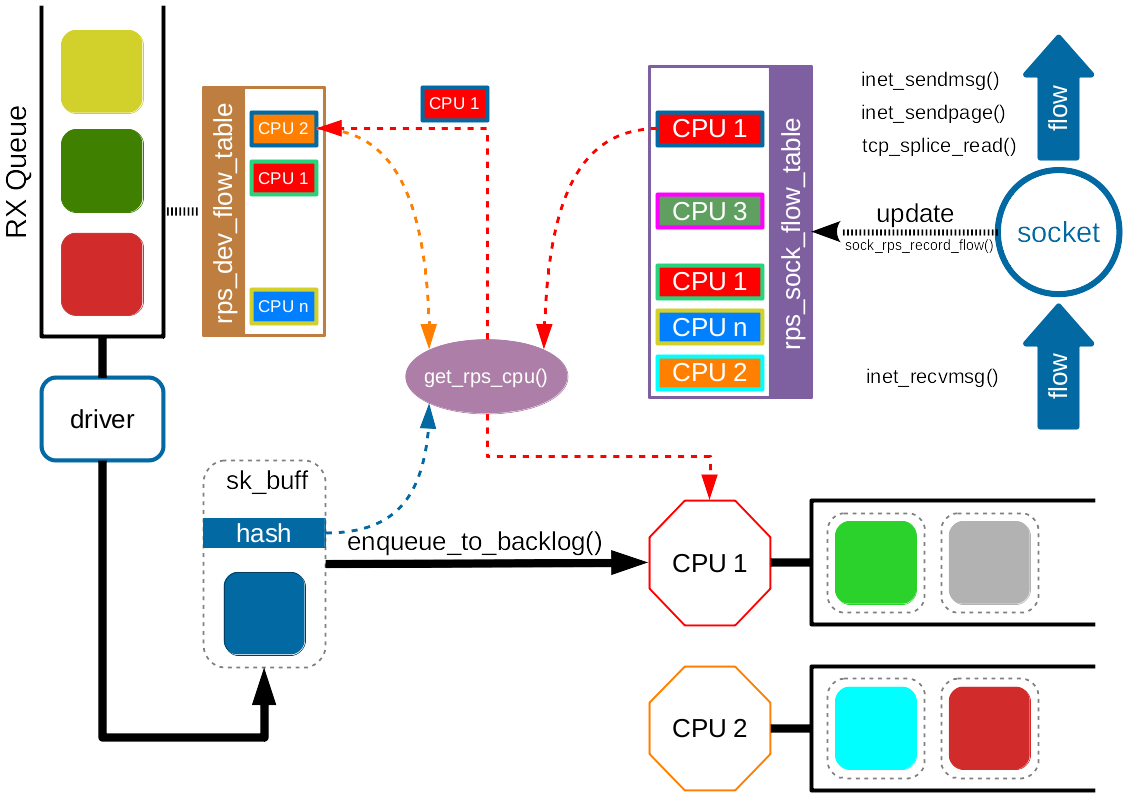
当选择处理数据包的 CPU 时,首先检查 rps_sock_flow 表和 rps_dev_flow 表中对应的 CPU 值是否相同。如果一样,说明进程还是运行在相同的 CPU 上,仍将数据包放在该 CPU 的队列上,没有问题。如果不一样,那么就看以下三个情况:
- 现在的 CPU 队列头计数器 ≥
rps_dev_flow表中的队列尾计数器。 - 现在的 CPU 未被设置 (≥
nr_cpu_ids)。 - 现在的 CPU 下线了。
如果上面任意一条满足,就将现在的 CPU 更新为 Desired CPU (即 rps_sock_flow 表中的值)。否则,仍在原(现) CPU 上执行。
直观的理解上面的判断机制,那就是:当进程切换 CPU 时,先判断原 CPU 队列上有没有未处理完的包,如果有就不切换;如果没有,就切换。
Linux 内核编译可通过允许 CONFIG_RPS 来使能该功能,一般默认允许。但要是想让 RFS 真正工作,还需要进行配置上面提到的两个表,他们的配置路径分别为:
|
|
rps_sock_flow_entries 的数量应该跟活跃流的数量相当,然后四舍五入取二的指数值。进一步,文档建议对于一般负载的服务器,值取为 32768 (2^15) 效果比较好。对于 rps_flow_cnt 的取值应该参考 rps_sock_flow_entries,因为前者是每个队列一个,后者是全局的,所以只要将 rps_flow_cnt 取为 rps_sock_flow_entries / N 就行,其中 N 为队列数。关于该建议,本人的理解是:最好能够给每一个活跃的流都能分配一个表项,使其能够准确找到对应的 CPU。
Accelerated RFS
Accelerated RFS 之于 RFS 相当于 RSS 之于 RPS。Accelerated RFS 在硬件上就可以选择正确的队列,随后触发该数据包所属流所在的 CPU 的中断。由此可见,如果想要在硬件上实现队列选择,我们需要一个从流到硬件队列的对应关系。
从上文可知,我们已经有了一个从流到 CPU 的映射关系,记录在 rps_dev_flow 表中。然后,我们也有 CPU 和硬件队列的关系,通过 /proc/irq/<irq_num>/smp_affinity 进行配置。
rps_dev_flow 表中存储的信息,如果该表被更新,说明有某个进程被创建,或者进程连同协议处理完全迁移到了一个新的 CPU。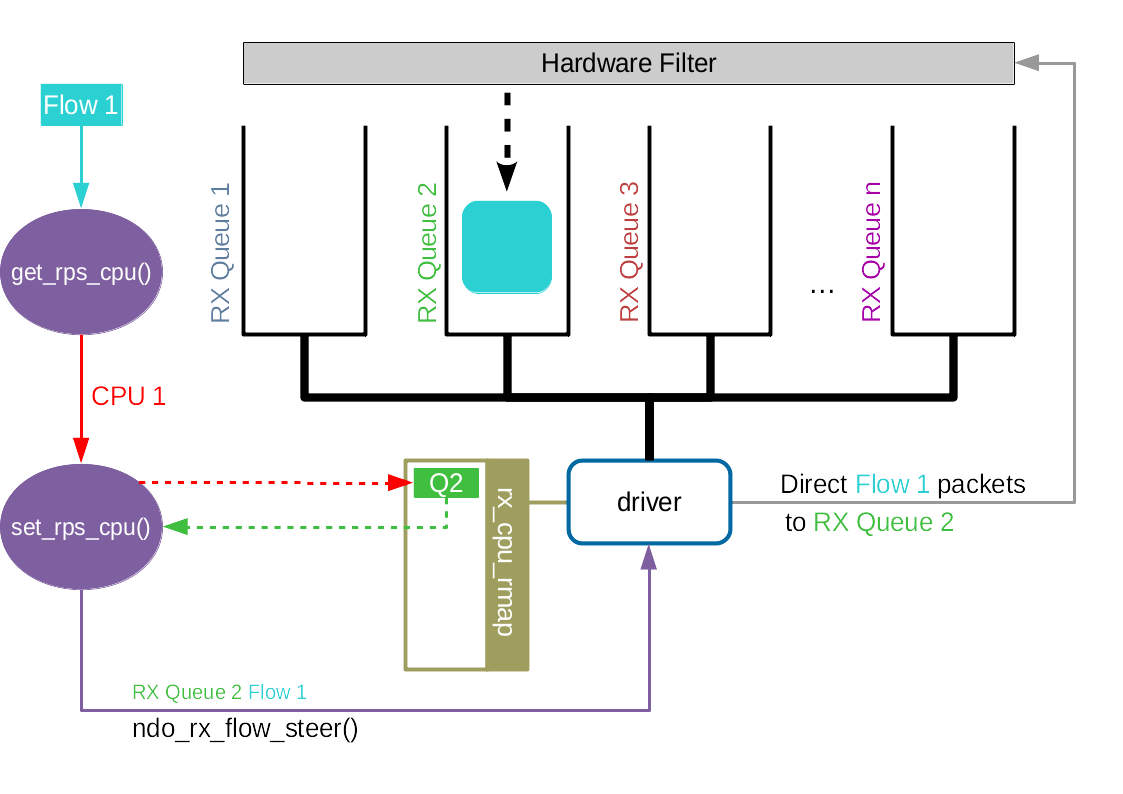
每当 rps_dev_flow 表中的条目被更新,网络协议栈就会调用驱动中的 ndo_rx_flow_steer 函数来更新流到硬件队列的对应关系。
Accelerated RFS 需要在编译阶段使能 CONFIG_RFS_ACCEL,并且需要硬件和驱动的支持。此外,还需要使用 ethtool 设置 ntuple 过滤。其他的就不需要配置了。
总结
回顾一下这些机制之间的关系。首先是 RSS/RPS,该机制在接收数据包的时候,通过手动配置,甚至是根据负载情况的自动配置(如 irqbalance),来把数据包的处理负载均匀分配到不同的 CPU 上。RSS/RPS 仅根据负载大小进行判断,但是这可能导致从协议栈处理到上层应用处理之间数据包的转移。
因此 RFS/aRFS 更进一步,在进行 CPU 选择的时候考虑上层应用所处位置,对每一个流都配置一个 Desired CPU。因此,在为数据包选择 CPU 的时候,会优先选择 Desired CPU。
参考
- Scaling in the Linux Networking Stack — The Linux Kernel documentation
- Toeplitz Hash Algorithm - Wikipedia
- 8.7. Receive Packet Steering (RPS) Red Hat Enterprise Linux 6 | Red Hat Customer Portal
- SMP IRQ affinity — The Linux Kernel documentation
- Linux Network Scaling: Receiving Packets (garycplin.blogspot.com)